Apify vs Bright Data: Which Web Scraper is Better in 2026?
An honest comparison between Apify and Bright Data. Which platform offers better scraping capabilities, proxies, and pricing?
As an Apify affiliate, we may earn a commission from qualifying purchases made through our links, at no extra cost to you. We only recommend tools we believe in.
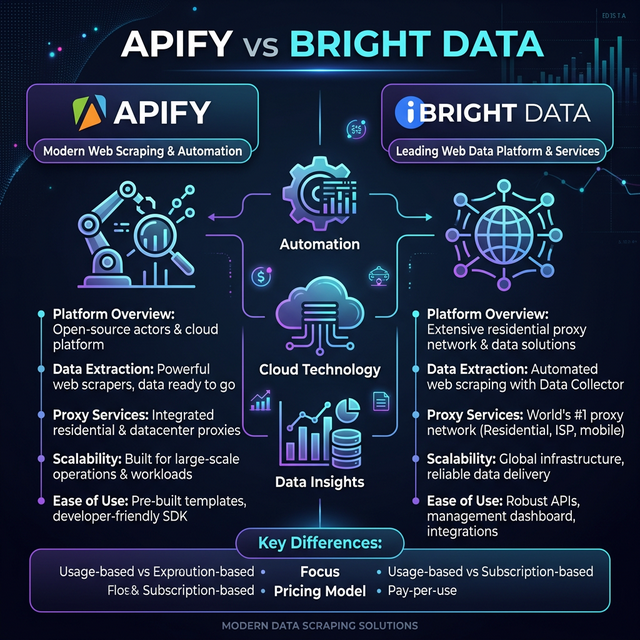
For 90% of teams, Apify is the stronger choice in 2026. It ships a marketplace of 39,000+ ready-to-run scrapers, transparent Compute Unit pricing that starts free, and enough built-in anti-bot capability to handle Google Maps, Amazon, LinkedIn, and most other major targets without additional setup. Bright Data wins exactly one scenario: when your engineering team needs the world’s largest residential proxy pool to defeat enterprise-grade bot defenses on the hardest possible targets. If that is not your situation, Apify will deliver results faster and at a fraction of the cost.
Quick Summary
Apify wins on:
- Ready-to-use scrapers (39,000+ Actors, zero code needed)
- Pricing — free tier, $29 Starter, predictable Compute Unit model
- Ease of use — non-engineers can run jobs in five minutes
- Integrations — native Zapier, Make, n8n, Google Sheets, webhooks
- Scheduling, storage, and monitoring all built in
Bright Data wins on:
- Proxy network scale — 72M+ residential IPs, the industry’s largest
- Anti-bot bypassing for the hardest targets (Akamai, PerimeterX, DataDome)
- Pre-compiled dataset purchases with no scraping required
- Geographic IP precision for country/city-level targeting
Core Philosophy: Actor Marketplace vs Proxy Infrastructure
These platforms are not trying to win the same market, and understanding that is the key to picking the right one.
Apify is built around a simple insight: most data extraction needs are not unique. Hundreds of companies want Google Maps reviews. Thousands want Amazon product prices. Millions want contact data from business websites. Instead of every team writing the same scraper from scratch, Apify built a marketplace — the Actor Store — where community developers publish maintained, tested scrapers that anyone can run on demand. You bring the target URL and the desired output format; Apify brings the scraper, the infrastructure, and the proxy rotation.
As of mid-2026, there are over 39,000 public Actors on the store covering every major data source: social media platforms, mapping services, e-commerce sites, job boards, news aggregators, business directories, SERP data, and thousands of niche vertical sources. The platform handles scheduling, retries, storage, and output delivery. A non-engineer can extract structured data from a major website in under ten minutes.
Bright Data is built around a different insight: the hardest part of scraping at enterprise scale is not writing the extraction logic — it is getting the HTTP request through without being blocked. Their core product is the proxy network itself: 72 million+ residential IPs sourced through an opt-in SDK embedded in consumer applications, plus datacenter and mobile IP pools. Every higher-level product they offer (Web Unlocker, Scraping Browser, SERP API) is layered on top of that network advantage.
Bright Data assumes you are a technical team that will write your own scraping code. They provide the infrastructure for the request layer; you provide everything else.
This means comparing the two directly on any single dimension will always mislead. The honest comparison is: do you need a platform that handles the full scraping pipeline end-to-end, or do you need a best-in-class proxy infrastructure layer on top of which you will build your own pipeline?
Feature Comparison Table
| Feature | Apify | Bright Data |
|---|---|---|
| Ready-to-run scrapers | 39,000+ public Actors | ~30 dataset types + SERP API |
| No-code data extraction | Full UI for any Actor | Datasets only |
| Custom scraper support | SDK + cloud runner (Node.js/Python) | Proxy APIs + Scraping Browser |
| Proxy network size | Datacenter + residential (shared pool) | 72M+ residential IPs (world’s largest) |
| Anti-bot bypass | Built into most Actors; Apify Proxy rotates automatically | Web Unlocker + Scraping Browser (best-in-class) |
| Managed browser | Playwright/Puppeteer in cloud Actor runs | Scraping Browser (remote, Playwright-compatible) |
| Scheduling | Built-in, cron-based, UI-configurable | API only |
| Storage | Dataset + KeyValue store included | External storage required |
| Webhooks / integrations | Zapier, Make, n8n, Slack, Sheets, GitHub, S3, BigQuery | API-based only |
| Free tier | $5/month credits, no card required | 7-day trial (qualifying businesses only) |
| Pricing model | Compute Units (CPU + RAM + time) | Bandwidth ($/GB transferred) |
| Entry-level paid plan | $29/month (Starter) | ~$500+/month (typical minimum business spend) |
| Scale plan | $199/month | Enterprise contracts |
| Target audience | Non-technical teams + developers | Engineering teams with custom pipelines |
| Dataset purchases | Not available | Available (LinkedIn, Amazon, etc.) |
| Best for | Structured data from named sites, fast | Enterprise proxy infra, hardest anti-bot targets |
Ease of Use Deep-Dive
The usability gap between these platforms is not a marginal difference — it is a category difference.
Getting started on Apify
- Go to apify.com and sign up (no credit card needed)
- Open the Actor Store and search for your target site
- Click the Actor, enter your search query or URL in the input form
- Click Run
- Download results as CSV, JSON, or Excel from the results panel
A user with no technical background can complete this in under ten minutes. The Actor handles proxy selection, anti-bot bypass, pagination, and output formatting automatically. If the run fails, the error message explains why in plain English.
Getting started on Bright Data
- Apply for a Bright Data business account (trial requires qualification)
- Once approved, obtain proxy credentials from the dashboard
- Write a scraper in Python or Node.js using Playwright or Puppeteer
- Configure your scraper to route through the Scraping Browser endpoint using your credentials
- Handle response parsing, pagination, and data storage yourself
- Set up hosting (AWS, GCP, or Bright Data’s limited cloud runner)
- Build a scheduling mechanism (cron, Airflow, or similar)
This is not a complaint about Bright Data — it is simply what the product is. Bright Data sells infrastructure, not a turn-key solution. If your team has experienced scraping engineers, this flow is entirely normal. If it does not, Bright Data is the wrong tool.
The one scenario where Bright Data is easier
If the exact dataset you need exists in Bright Data’s pre-compiled marketplace — LinkedIn company profiles, Amazon product listings, specific e-commerce categories — you can purchase and download it immediately with no scraping at all. For this narrow use case, Bright Data is actually simpler than Apify because there is nothing to run.
Proxy Networks and Anti-Bot Bypassing
This is Bright Data’s domain, and it is worth being specific about where the advantage actually applies.
Bright Data’s proxy infrastructure
Bright Data operates the largest ethically-sourced residential proxy network in the world: 72 million+ IPs spread across 195+ countries. These are real consumer devices running Bright Data’s SDK as part of opt-in apps, which means requests routed through them look identical to real user traffic from real residential ISPs. This matters because aggressive anti-bot systems like Akamai Bot Manager, PerimeterX, and DataDome analyze IP reputation, ASN classification, and behavioral patterns — and datacenter IPs from AWS or Azure fail those checks almost immediately.
Their Web Unlocker product adds a managed layer on top: it handles TLS fingerprinting to match real browser signatures, rotates headers and cookies across requests, and solves CAPTCHAs automatically. Their Scraping Browser goes further, presenting as a full Chromium session running from a residential IP, which defeats even JavaScript-based fingerprinting checks.
For the top 5% of hardest targets — major financial data platforms, travel aggregators running enterprise anti-bot stacks, LinkedIn at significant scale — Bright Data is simply more capable than any other option on the market.
Apify’s proxy capabilities
Apify provides a shared proxy network including datacenter and residential IPs with automatic rotation. For most popular websites, this is sufficient. Actors published on the store are maintained by their authors specifically to handle anti-bot measures on their target sites; the Google Maps Actor, for instance, has been battle-tested against Google’s anti-scraping systems for years.
The key difference: Apify’s residential proxies are a shared pool, not the 72-million-IP network that Bright Data operates. For targets that are not aggressively blocking, this makes no practical difference. For the subset of targets that fingerprint and ban IPs based on reputation scoring, Bright Data’s network depth provides a meaningful advantage.
The hybrid approach
Because Apify supports custom proxy configuration in Actor inputs, many teams use both: they run Apify Actors for the vast majority of their data needs, but route those Actors through Bright Data residential proxies for specific high-security targets. This gives you the convenience of the Actor marketplace plus the best-in-class IP coverage where you genuinely need it.
Pricing: Real-World Cost Comparison
The pricing models are structured so differently that side-by-side sticker price comparison is misleading. Working through a concrete example is the only honest approach.
Apify pricing structure
Apify bills in Compute Units (CU). One CU equals one Actor run consuming 1 GB of RAM for one hour. Most scraping tasks run well under one CU.
| Plan | Monthly Price | Compute Credits | Residential Proxy Rate |
|---|---|---|---|
| Free | $0 | $5 credit | $8/GB |
| Starter | $29 | $29 credit | $8/GB |
| Scale | $199 | $199 credit | $8/GB |
| Business | Custom | Custom | Custom |
Datacenter proxies are cheaper and often included in Actor runs. Residential proxies are used only when specifically needed.
Bright Data pricing structure
Bright Data charges per GB of data transferred through their network.
| Product | Pay-As-You-Go | Committed Monthly |
|---|---|---|
| Residential proxies | $8.40/GB | $5.88/GB |
| Datacenter proxies | $0.90/GB | $0.50/GB |
| Scraping Browser | $8.40/GB + per-request fee | Custom |
| Web Unlocker | $3.00/GB | Custom |
There is no meaningful free tier. The trial is time-limited and gated to qualifying business accounts. Minimum realistic monthly spend for a business is $300–500+ before you have written a single line of scraping code.
Worked example: 10,000 Google Maps listings
Let us cost out extracting 10,000 Google Maps business listings (name, address, phone, rating, review count, website) on each platform.
On Apify using the Google Maps Scraper:
- Average page weight via residential proxies: ~80 KB per listing
- Total proxy bandwidth: 10,000 × 80 KB = ~800 MB ≈ 0.8 GB
- Residential proxy cost at Starter tier: 0.8 GB × $8 = $6.40
- Compute time: ~45 minutes at 2 GB RAM = 1.5 CU ≈ $1.50
- Engineering time: zero (pre-built Actor)
- Total: ~$7.40, well within the $29/month Starter plan
On Bright Data using Scraping Browser + custom script:
- Average rendered page weight (full DOM): ~350 KB per listing
- Total bandwidth: 10,000 × 350 KB = ~3.5 GB
- Residential bandwidth at committed rate: 3.5 GB × $5.88 = $20.58
- Scraping Browser per-request fee: 10,000 × ~$0.001 = $10.00
- Developer time to write, test, and maintain scraper: not zero
- Storage and scheduling infrastructure: not zero
- Total: ~$30.58+ before engineering and infrastructure costs
Apify wins on direct cost by roughly 2.5×, and by a much larger factor when engineering overhead is included.
Integrations and API Access
Apify is built for integration from day one. Every Actor exposes a REST API automatically, and the platform ships native connectors for the tools modern data teams actually use:
- Zapier, Make (Integromat), n8n — trigger Actor runs from any workflow tool, push results to any destination
- Google Sheets — export directly from any Actor result dataset
- Slack — receive notifications when runs complete, fail, or produce alerts
- GitHub — sync Actor code to repositories, enable CI/CD for Actor development
- Snowflake, BigQuery, Amazon S3 — push results directly into data warehouse pipelines
- Webhooks — fire any HTTP endpoint on run completion with full result payload
This means a non-engineer can set up a weekly Google Maps scrape that automatically updates a Google Sheet and sends a Slack notification — entirely within the Apify UI, with no code.
Bright Data integrates through API calls and proxy credential configuration. There is no workflow automation layer; teams are expected to build their own integration pipelines. For engineering teams that are already building custom data pipelines, this is a reasonable expectation. For everyone else, it is significant additional work.
Who Should Choose Apify
Apify is the right choice for the overwhelming majority of teams extracting data from the web in 2026. Specifically:
- You need data from a named, popular website and want it today. There is almost certainly an Actor on the store for your target. Google Maps, Amazon, LinkedIn, Instagram, TikTok, Zillow, Yelp, Indeed, Crunchbase — all covered.
- Your team includes non-engineers. The Actor UI is as simple as a web form. No proxy configuration, no coding, no infrastructure knowledge required.
- You want scheduling, storage, and monitoring included. Apify handles all of this natively. Set up a cron schedule, and your data arrives automatically.
- Your budget is under $500/month and you want predictable costs. The free tier ($5 credits) is genuinely useful. The $29 Starter plan covers most small-to-medium workloads. The $199 Scale plan covers serious production use.
- You want to avoid maintaining scraper code. Actor authors maintain their scrapers against site changes. You do not carry that burden.
- You need integrations with your existing stack. Zapier, Make, webhooks, Google Sheets — it is all native.
Browse the full scraper library to see if your target is already covered before making a decision.
Who Should Choose Bright Data
Bright Data is the right choice for a narrower, more technical buyer profile:
- You are building a proprietary scraping system and need best-in-class proxy infrastructure. If your competitive advantage requires custom extraction logic that you cannot share with a marketplace, and you need the best possible proxy network under it, Bright Data is the infrastructure layer.
- Your targets deploy Akamai Bot Manager, PerimeterX, DataDome, or similar enterprise anti-bot stacks. For this subset of targets, Bright Data’s residential IP depth and Web Unlocker bypass capability is genuinely superior to anything else on the market.
- You need geographic precision at the IP level. 72M+ residential IPs across 195 countries means you can target specific cities or ISPs for geo-localized data.
- You want to purchase pre-compiled datasets. If you need LinkedIn company profiles or Amazon product snapshots and do not want to run a scraper at all, Bright Data’s dataset marketplace is the cleanest option.
- You have a dedicated scraping engineering team and a budget to match. $500+/month is a realistic starting point; serious use cases typically exceed $1,000/month in proxy costs alone.
See the comparisons hub for alternatives if neither platform fits your exact needs.
Verdict
Apify wins this comparison for the vast majority of teams in 2026. The 39,000-Actor marketplace eliminates engineering overhead that makes web scraping painful; the pricing is transparent and affordable from the free tier through serious production workloads; and the integration ecosystem means your data flows automatically into the tools your team already uses. The $5/month free tier provides more practical value than Bright Data’s business-gated trial.
Bright Data is genuinely excellent — for the specific buyer it is built for. If your problem is bypassing the hardest anti-bot defenses in the world with a 72-million-IP residential network, there is nothing better. But that is a narrow, high-budget, technically demanding use case.
If you are not sure which fits your situation, the right answer is to start with Apify. Sign up for free and get $5 in monthly credits — no credit card required. Run a few Actors against your target sites. You will know within an hour whether the standard tooling covers your needs. If it does not, the hybrid approach — Apify Actors routing through Bright Data residential proxies — gives you the best of both platforms.
Check the Apify pricing guide for a detailed breakdown of costs at different scales, or browse all ready-made scrapers to find your specific use case.
Related Resources
🛠️ Recommended Tools
Google Maps Scraper
Extract business data from Google Maps including names, addresses, phone numbers, reviews, and ratings. Perfect for B2B lead generation.
Web Scraper
Crawl any website using a browser and extract structured data with custom JavaScript code.
Website Content Crawler
Advanced website crawler extracting clean, structured content in Markdown, JSON, or plain text for AI and LLM applications.
Tags
ParseFlow
Web Scraping & Automation Studio
Years of hands-on experience building and maintaining web scrapers. We publish real, actively-used tools on the Apify Store under the Website Harvester brand — including our Twitter Scraper and Articles Extractor actors — alongside curating and reviewing the broader Apify ecosystem here on ParseFlow.
Related Articles
Apify MCP Server: Give Your AI Agent Access to 39,000+ Web Scrapers
How to connect Claude, GPT-4, and other AI agents to Apify's MCP server and give them access to 39,000+ real-time web scrapers — in under 10 minutes.
Apify Pricing Explained 2026: Cost, Compute Units & Is It Free?
A complete guide to Apify's 2026 pricing model. Understand Compute Units (CUs), proxy costs, and how to start scraping the web for free.
Apify vs Octoparse: Which No-Code Scraper Wins in 2026?
Comparing Apify and Octoparse for no-code web scraping. Learn the differences in usability, scale, cloud execution, and pricing.